

Photo by Jainath Ponnala on Unsplash
Lessons learned from picking the right Java driver for Amazon ElastiCache for Redis - Part 2
Exploring failover scenarios with Lettuce


In part one of this series we looked at Jedis as the Java-based Redis driver when used in combination with ElastiCache for Redis in clustered mode. We learned that during a failover Jedis takes some time to figure out what the new primary is before it can restore the connection to the ElastiCache cluster. In this post, I’ll share some of the lessons learned from switching to Lettuce as the driver for our Java-based application.
A different driver
Lettuce, a Java-based driver for Redis, is the default driver for Redis when working with Spring Framework. Lettuce is a fully non-blocking Redis client built with Netty providing Reactive, Asynchronous and Synchronous Data Access.
As a driver, we found it quite similar to use compared to Jedis. Configuring the client was pretty easy to do as you can see in the code below.
RedisURI redisUri = RedisURI.Builder.redis(REDIS_HOST)
.withSsl(true)
.build();
RedisClusterClient clusterClient = RedisClusterClient.create(redisUri);
StatefulRedisClusterConnection<String, String> connection = clusterClient.connect();
syncCommands = connection.sync();
With Jedis, we configured a connection pool, but as you might notice from the above code, we're not using a connection pool. Lettuce connections are designed to be thread-safe so one connection can be shared amongst multiple threads and Lettuce connections auto-reconnect by default. If needed you can still configure a connection pool, but we did not need it in our case.
Lettuce states to be cloud-ready, which sounds very promising.
Battle-tested with major Cloud-based Redis services. Lettuce adopts the specifics of various cloud offerings to seamlessly integrate for the best performance.
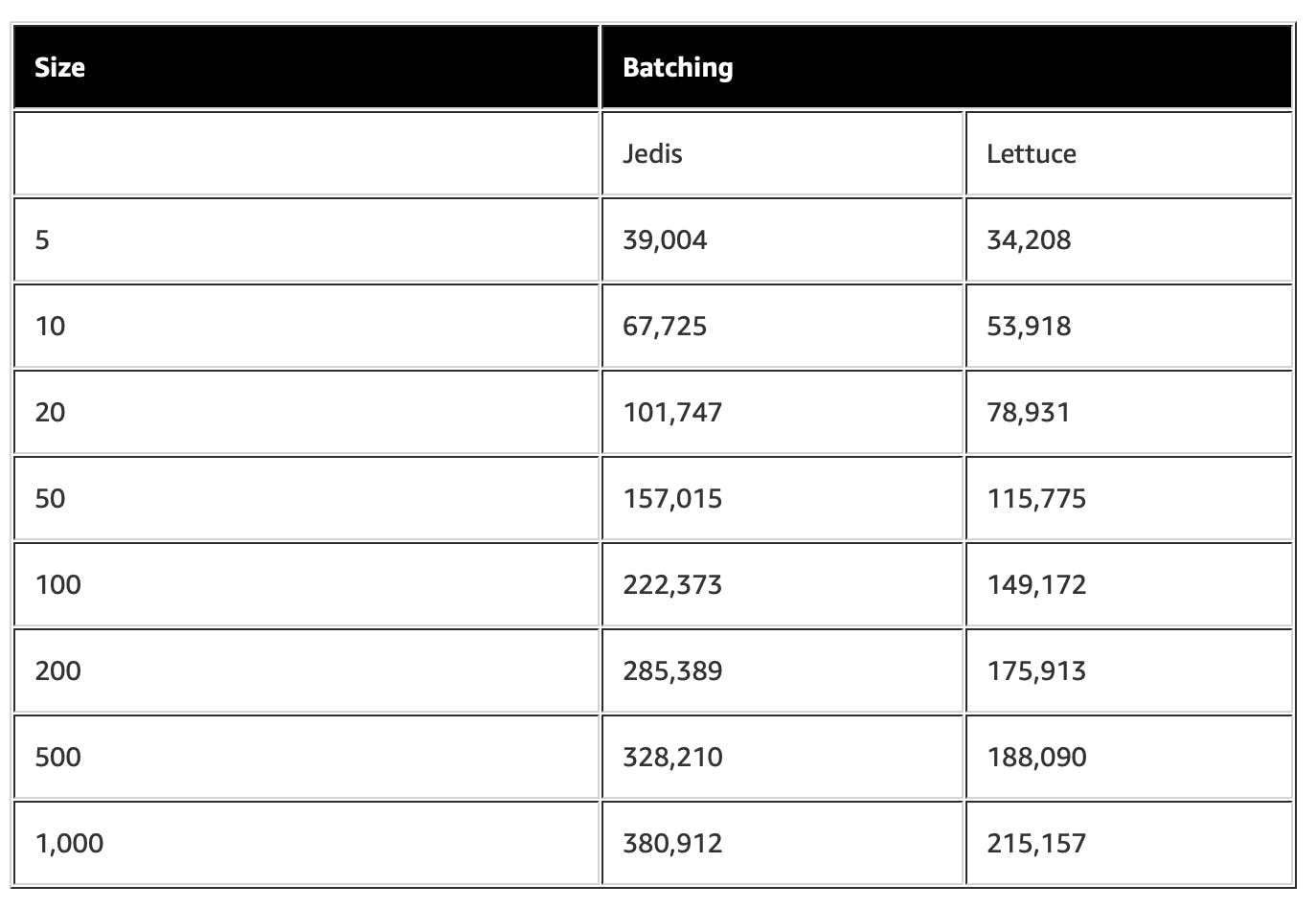
The AWS blog contains a solid article on ElastiCache for Redis client performance. In tests performed by the AWS team, we can see that Jedis was up to twice as fast as Lettuce. It's an interesting fact if performance is the 'only' concern you have.
Given the fact that Lettuce is built with Netty, we also immediately noticed quite an impact on the initialization time (cold start) of our lambda function. Netty is really fast while executing, but takes a bit of time to initialize. The new Lambda Snapstart functionality might help with that.
Instantiating an authorized connection with Lettuce took about 1500 ms, which is almost twice the time compared to Jedis.
For Lettuce, we will run the same test scenarios and we will keep track of the number of nodes in the cluster by returning the list of cluster nodes from our test lambda function. Our lambda spits out the current information about the cluster and the roles of the different nodes.
{
"nodes": "254eaace08fafb42d26750b8721d1fd5b152f0bd test-cluster-0001-001.test-cluster.ifrpha.euw1.cache.amazonaws.com:6379@1122 master,fail - 1679323815172 1679323813195 1 connected\n5f41504ecd68d90956060e219ebf8ec32782c4e2 test-cluster-0001-003.test-cluster.ifrpha.euw1.cache.amazonaws.com:6379@1122 myself,slave fa0e9e04c33409b48a8d486e27277bd313e01c27 0 1679323902000 3 connected\nfa0e9e04c33409b48a8d486e27277bd313e01c27 test-cluster-0001-002.test-cluster.ifrpha.euw1.cache.amazonaws.com:6379@1122 master - 0 1679323903029 3 connected 0-16383\n"
}
Failover scenarios
Just like with Jedis, we wanted to test Lettuce in combination with the two following scenarios:
- A primary node failure.
- A maintenance upgrade that would rotate and update the nodes to a new version of Redis (from 6.0.x to 6.2.x).
Primary node failover
Just like in part one we will test the impact of a primary node failover and see how the Lettuce client is handling the situation. Lettuce appeared to be quite configurable and flexible, so we tested a couple of different scenarios.
Attempt 1: Simple settings
Our first attempt was with the simple client configuration as previously shown. We do not use any connection pool and have a very simple synchronous client while connecting to the cluster. We connect with the cluster configuration endpoint, so that ElastiCache for Redis can give us a view of the cluster topology. To analyze the impact of the failover we started using Cloudwatch Logs Insights. It allowed us to scan for the number of exceptions during the failover. By using the following query on our lambda log group we could see all log messages that contained a Java Exception.
fields @timestamp, @message, @logStream, @log
| filter @message like /(?i)(Exception)/
| sort @timestamp desc
| limit 2000
From what we could see there are quite some Exceptions being thrown during the failover, however, the exceptions occurred for about 2 minutes, after which the client was able to properly handle the requests.

Most of the exceptions fall in the category of timeouts and connection errors:
io.lettuce.core.RedisCommandTimeoutException: Command timed out after 1 minute(s)
and
io.lettuce.core.cluster.topology.DefaultClusterTopologyRefresh$CannotRetrieveClusterPartitions: Cannot retrieve cluster partitions
Both seemed to be related to the fact that Lettuce was trying to fetch the values from the primary/master cluster node and trying to reconnect with the master node that just went 'down'.
Attempt 2: Topology refresh
Lettuce has a feature called topology refresh, which allows the client to poll the server for an updated view of the cluster topology. We were wondering if enabling this would have a big impact on the fact that our client was losing its connection to the primary node.
ClusterTopologyRefreshOptions topologyRefreshOptions = ClusterTopologyRefreshOptions.builder()
// default refresh period = 60 seconds
.enablePeriodicRefresh()
.enableAllAdaptiveRefreshTriggers()
.build();
clusterClient.setOptions(
ClusterClientOptions
.builder()
.socketOptions(SocketOptions.builder().build())
.timeoutOptions(TimeoutOptions.enabled())
.topologyRefreshOptions(topologyRefreshOptions)
.pingBeforeActivateConnection(true)
.build()
);

Based on the logs insights graph we could see that there was a certain positive impact as the number of errors produced during the failover is less and also less in volume, but our application was still having read issues when reading from the cluster. The logs were similar and still quite substantial in volume so we wanted to learn more about the other different configuration options.
Attempt 3: Changing read preference
By default Lettuce, just like Jedis, reads from the primary node / shard. However, Lettuce has an additional option, that Jedis does not have, called read preference. If your workload permits, you can tell Lettuce to also read from replica nodes when the primary node is down. In a read-heavy cluster, this can be a very valuable setting.
With the connection.setReadFrom you have the option to select a specific preference. Some of the available options include:
UPSTREAM (primary node)
UPSTREAM_PREFERRED (primary/upstream and fall back to a replica if the upstream is not available)
REPLICA_PREFERRED (read preferred from replica and fall back to upstream if no replica is available)
REPLICA (only read from read replicas)
In our case we configured it to use UPSTREAM_PREFERRED, so we would failover to the replicas in case of the primary node failover.
StatefulRedisClusterConnection<String, String> connection = clusterClient.connect();
// removed topology refresh for readability (it's included in the actual configuration)
connection.setReadFrom(ReadFrom.UPSTREAM_PREFERRED);
syncCommands = connection.sync();
We could see a clear impact on the number of error messages produced during the failover.

From the logs, we could still see some error messages indicating that the cluster was down during the failover. Why were we still getting those messages?
Attempt 4: Read preference and allow reads when the cluster is 'down'
After doing a bit more research we learned that Redis by default does not allow read operations from replicas when the primary node / shard is marked as 'down'. However, for read-heavy workloads, this might not be an issue. If you want you can allow reads when the cluster is marked as down by changing a parameter.
- cluster-allow-reads-when-down
<yes/no>: If this is set to no, as it is by default, a node in a Redis Cluster will stop serving all traffic when the cluster is marked as failed, either when a node can't reach a quorum of masters or when full coverage is not met. This prevents reading potentially inconsistent data from a node that is unaware of changes in the cluster. This option can be set to yes to allow reads from a node during the fail state, which is useful for applications that want to prioritize read availability but still want to prevent inconsistent writes. It can also be used when using Redis Cluster with only one or two shards, as it allows the nodes to continue serving writes when a master fails but automatic failover is impossible.
In AWS CDK you can define a custom parameter group which you provide to your cluster. You can base your parameter group based on the default available groups; for instance "default.redis6.x.cluster.on".
CfnParameterGroup parameterGroup = CfnParameterGroup.Builder
.create(this, "elasticache-param-group")
.cacheParameterGroupFamily("redis6.x")
.description("Custom Parameter Group for redis6.x cluster")
.properties(
Map.of(
"cluster-enabled", "yes",
"cluster-allow-reads-when-down", "yes")
)
.build();
CfnReplicationGroup replicationGroup = CfnReplicationGroup.Builder.create(this, "replicationgroup-id")
.cacheNodeType(props.getCacheNodeType())
.engine("redis")
.engineVersion(props.getEngineVersion())
.autoMinorVersionUpgrade(true)
.automaticFailoverEnabled(true)
.cacheParameterGroupName(parameterGroup.getRef())
.multiAzEnabled(true)
.atRestEncryptionEnabled(true)
.transitEncryptionEnabled(true)
...
After configuring the above changes we noticed that while we were still doing 30 requests a second during the failover, there was a 'seamless' switch over to the replica nodes and our lambda function was operating as normal. No errors were produced during the fail-over. That looked promising!
Cluster engine version upgrade
The next scenario was running a cluster engine upgrade. To validate the impact of a version upgrade we migrated from version Redis 6.0.x to 6.2.x. We learned that just like with Jedis we did not see any obvious impact (at least after we configured all of the above options). The upgrade happened, while the service was serving a constant load of 30 requests per second, without producing any errors.
Summary
By doing this exercise with Lettuce we learned that Lettuce has some advanced capabilities when it comes to reading from an ElastiCache for Redis cluster. By tweaking the client and the server configuration we were able to perform a primary node failover without generating any errors for reads on our cluster. However, if performance is more important than availability you might want to stick with Jedis as it seems to be up to 2x as fast for certain operations.